GPU 서버 한 대로 LLM 셀프호스팅 시작하기: Ollama·vLLM·Open WebUI 구축과 TCO로 보는 API 비용 vs 운영비
55 views
# GPU 서버 한 대로 LLM 셀프호스팅 시작하기: Ollama·vLLM·Open WebUI 구축과 TCO 분석
GPU 한 대로 LLM을 셀프호스팅하는 행위는 비용 절감의 기술이 아니다. 통제·성능·책임의 경계를 내부로 끌어오는 경영적 선택이다. 따라서 "돌아가느냐"가 아니라 "어떤 조건에서, 어떤 구조로, 어떤 함의를 감수하며"를 따져야 한다.
이 글은 네 개 질문으로 전개한다. 셀프호스팅이 왜 다시 등장했는가. Ollama·vLLM·Open WebUI로 최소 시스템을 어떻게 구성하는가. TCO로 API 비용과 운영비를 어떻게 비교하는가. 기술 선택이 조직의 사고방식을 어떻게 바꾸는가.
---
## 1. "API가 편한데 왜 굳이 GPU를 사나"라는 질문의 배경
LLM 도입 초기에 API는 정답처럼 보인다. 초기 비용이 낮고, 스케일링이 자동이며, 운영 인력이 필요 없다. 그러나 실무가 누적되면 패턴이 반복적으로 나타난다.
### 비용의 비선형성
LLM은 기능이 아니라 사용 습관을 만든다. 요약·분류에서 시작해 사내 문서 질의응답, 코드 리뷰, CS 자동화로 확장된다. 이때 비용은 사용량에 선형으로 비례한다. 내부 기능이 늘수록 "토큰이 새는 지점"도 늘어난다.
API 과금은 입력/출력 토큰에 연동되며, 팀이 늘수록 거버넌스가 약해져 낭비가 구조적으로 발생한다.
### 지연과 체감 품질
사용자가 체감하는 것은 평균 응답이 아니라 "가끔 한 번씩" 길어지는 지연이다. 네트워크와 공급자 혼잡에 따라 꼬리 지연이 발생하면 제품은 안정적으로 느껴지지 않는다. 셀프호스팅은 절대 성능이 아니라 지연의 통제 가능성을 제공한다.
### 통제와 감사
보안팀·법무팀이 관여하기 시작하면 질문이 달라진다. "나간 데이터가 무엇인지", "보관되는지", "학습에 쓰이는지", "삭제 요청을 어떻게 수행하는지"가 핵심이 된다.
셀프호스팅은 완전한 안전을 보장하지 않지만, 책임의 경계를 명확히 내부로 가져온다.
---
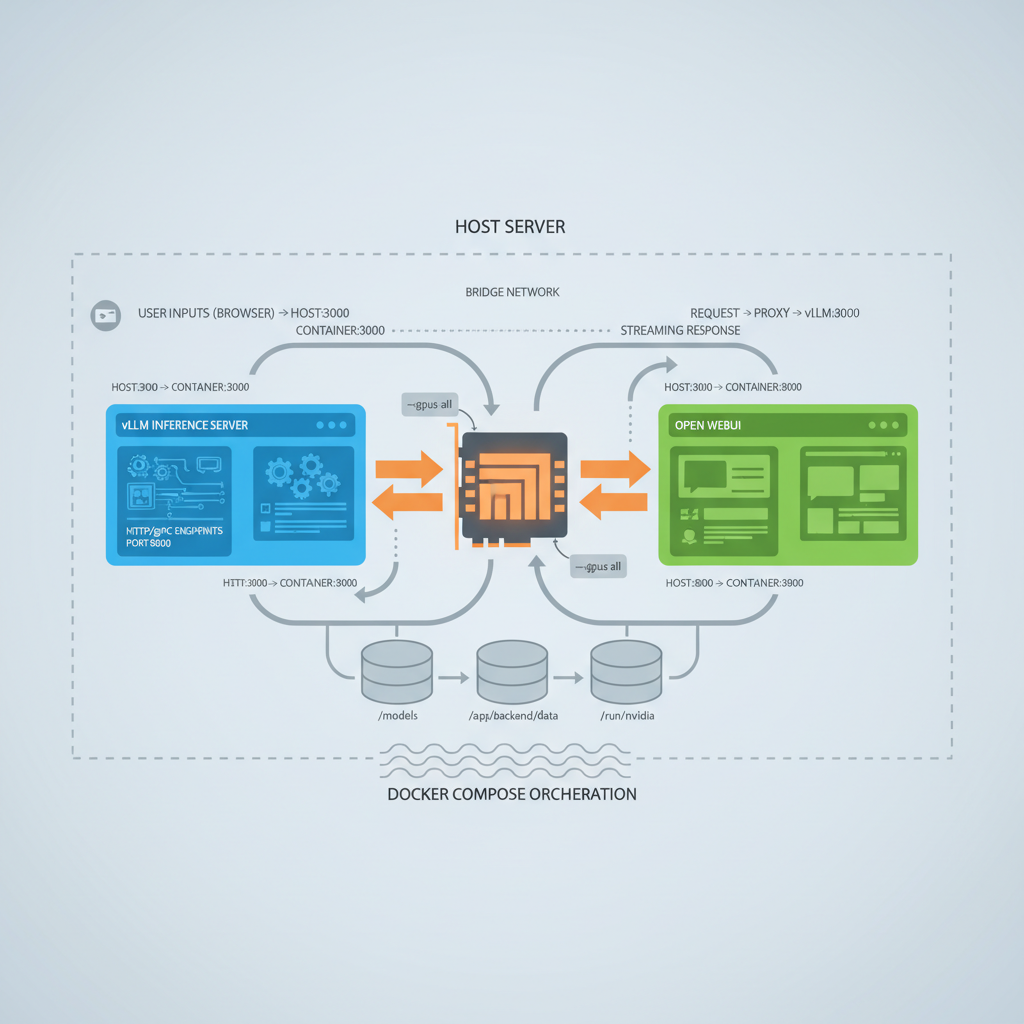
## 2. GPU 1대 최소구성 — Ollama·vLLM·Open WebUI
여기서 말하는 "GPU 서버 한 대"는 대개 다음 범주다.
- GPU: 24GB(RTX 4090) ~ 48GB(RTX 6000 Ada/L40S) ~ 80GB(A100/H100)
- CPU: 16~32코어
- RAM: 64~256GB
- NVMe: 1~4TB
목표는 한 대의 서버에서 모델 서빙과 UI, 그리고 API를 안정적으로 제공하는 것이다. 운영의 핵심은 "단순함"이며, 단순함은 장애를 다루는 비용을 낮추는 방식이다.
### 세 가지 역할 분담
**Ollama**는 모델을 쉽게 내려받고 실행하는 개발자 친화적 런타임이다. 시작 속도가 빠르지만 고동시성 환경에는 한계가 있다.
**vLLM**은 생산 환경에서 강력하다. PagedAttention 기반으로 KV 캐시 효율이 좋고 동시성 처리에 유리하다. OpenAI 호환 API를 제공해 기존 애플리케이션의 교체 비용을 낮춘다.
**Open WebUI**는 사내 사용자에게 대화·프롬프트·지식베이스·권한의 표면을 제공한다. 기술의 채택 비용을 줄인다.
실무에서는 두 가지 패턴으로 정리된다.
- PoC/개인용: Ollama + Open WebUI
- 팀/서비스용: vLLM + Open WebUI
### Docker Compose 기반 구성
단일 서버의 장점은 단순함이고, 단점은 단일 장애점이다. 그러나 시작 단계에서는 "장애를 분산"하기보다 "원인을 추적"할 수 있어야 한다.
```yaml
services:
vllm:
image: vllm/vllm-openai:latest
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
volumes:
- /data/models:/models
command: >
--model /models/Qwen2.5-7B-Instruct
--served-model-name qwen2.5-7b
--host 0.0.0.0
--port 8000
--gpu-memory-utilization 0.90
--max-model-len 8192
ports:
- "8000:8000"
openwebui:
image: ghcr.io/open-webui/open-webui:main
depends_on:
- vllm
environment:
- OPENAI_API_BASE_URL=http://vllm:8000/v1
- OPENAI_API_KEY=local
- WEBUI_AUTH=true
volumes:
- /data/openwebui:/app/backend/data
ports:
- "3000:8080"
```
운영에서 중요한 것은 옵션의 의미를 이해하는 일이다.
`--gpu-memory-utilization`은 VRAM을 얼마나 공격적으로 쓸지 결정한다. 높이면 OOM 위험이 커진다. `--max-model-len`은 컨텍스트 길이다. 길어질수록 KV 캐시가 커지고 동시성이 줄어든다.
### 모델 선택의 실무적 기준
셀프호스팅에서 모델 선택은 취향이 아니라 목적 함수다.
- 사내 문서 Q&A/RAG: 7B~14B + 좋은 임베딩 모델 + 재랭커
- 코드 보조: 코드 특화 모델
- 한국어 업무 문장: 다국어 instruct 계열 7B/14B
GPU 24GB 기준으로는 7B~14B(양자화 포함)가 현실적이며, 48GB 이상이면 32B도 운영 시야에 들어온다. 중요한 것은 "한 번에 하나의 거대 모델"이 아니라 "작은 모델을 여러 목적에 맞게 조합"하는 전략이다.
### 보안과 운영의 최소 원칙
- 외부 노출 최소화: vLLM 포트는 내부망으로 제한하고 역프록시로 통제
- 인증: Open WebUI 계정 정책과 SSO 연동
- 로깅: 프롬프트/응답 로그는 민감정보다. 저장 정책을 명시하고 최소화
- 업데이트: "최신"보다 "재현 가능"이 우선. 이미지 태그를 고정하고 변경을 기록
- 백업: WebUI 데이터와 모델 파일, 설정을 분리해 백업
---
## 3. TCO로 API 비용 vs 운영비를 같은 단위로 비교하는 법
비교가 실패하는 이유는 단순하다. API는 "사용량 기반 비용"이고, 셀프호스팅은 "고정비+운영비+기회비용"이다. 둘을 감정으로 비교하면 결론이 흔들린다. TCO(Total Cost of Ownership)로 같은 단위(월 비용, 연 비용)로 환산한다.
### TCO 프레임: 월간 총비용의 구성요소
셀프호스팅 월간 TCO는 다음으로 구성된다.
1. **자본비용의 감가상각**: 서버 구매비 / 사용기간(월)
2. **전력비**: 평균 소비전력(kW) × 사용시간 × 전기요금
3. **상면/회선/클라우드 대체비**: IDC 랙/회선, 네트워크/UPS 등
4. **운영 인건비**: 설치·업데이트·장애대응 시간 × 인건비
5. **리스크 비용**: 장애로 인한 손실, 보안 사고의 기대값
API 월간 비용은 비교적 단순하지만 다음이 추가된다.
- 토큰 비용(입력+출력)
- 로그/저장/프록시 비용
- 네트워크 egress
- 공급자 변경 비용(락인)
핵심은 "정확한 숫자"가 아니라 의사결정에 충분한 정확도다. ±20% 오차가 있어도 결론이 바뀌지 않게 만드는 것이 좋은 모델이다.
### 실전 계산 예시: 팀 내부 도구 기준
가정:
- GPU 서버 구매: 900만원(4090급 + CPU/RAM/NVMe)
- 감가상각: 36개월 → 월 25만원
- 평균 소비전력: 0.45kW
- 전기요금: 200원/kWh
- 월 전력비: 0.45 × 24 × 30 × 200 ≈ 65,000원
- 운영 시간: 월 6시간
- 내부 인건비: 시간당 6만원 → 월 36만원
- 기타(회선/백업): 월 10만원
월 TCO:
- 감가상각 25만원
- 전력 6.5만원
- 운영 36만원
- 기타 10만원
- **합계: 약 77.5만원/월**
이 숫자는 "GPU가 놀고 있어도 드는 비용"이다. 이제 API 비용과 비교하려면 월간 사용량을 토큰으로 환산해야 한다.
토큰 환산:
- 사내 사용자 30명
- 1인당 하루 20회 요청
- 요청당 평균 1,200토큰(입력 500 + 출력 700)
- 월 요청 수: 30 × 20 × 22영업일 = 13,200회
- 월 토큰: 13,200 × 1,200 ≈ 15,840,000토큰
API 단가가 "1M 토큰당 X원"이라면 월 API 비용은 15.84 × X원이다.
손익분기점: 15.84 × X ≈ 775,000원 → X ≈ 48,900원/1M 토큰
1M 토큰당 총단가가 약 4.9만원을 넘으면 셀프호스팅이 월 비용 기준으로 유리해질 가능성이 생긴다. 반대로 단가가 낮거나 운영 인건비가 크거나 사용량이 적으면 API가 합리적이다.
셀프호스팅의 경제성은 "모델이 싸서"가 아니라 사용량이 일정 수준을 넘고 운영을 표준화해 인건비를 통제할 때 발생한다.
### 비용 외의 결정 변수
TCO로도 결론이 안 나는 경우가 있다. 그때 남는 것은 비용이 아니라 가치다.
- **지연의 예측 가능성**: 내부망에서 1~2초로 고정되면 제품 설계가 바뀐다
- **데이터 통제**: 개인정보/영업비밀이 포함된 워크플로우에서 "외부 전송 금지"는 비용을 초월한다
- **커스터마이징**: 시스템 프롬프트, 금칙어, 출력 포맷, 내부 정책을 강제하기 쉬워진다
- **락인 회피**: OpenAI 호환 API로 추상화해두면 공급자 변경 비용이 떨어진다
---
## 4. 셀프호스팅은 조직의 사고 체계를 바꾼다
기술은 도구이지만 도구는 사용자의 사고를 재구성한다. 외부 API를 쓰면 실패의 원인이 외부로 밀려나지만, 셀프호스팅을 하면 실패가 내부로 들어온다. 이 변화는 불편하지만 생산적이다.
### 책임의 귀속
API 시대에는 공급자의 모델 품질이 문제처럼 보이기 쉽다. 셀프호스팅에서는 질문이 바뀐다.
프롬프트 설계, RAG 품질, 문서 정합성, 권한 모델, 관측성이 모두 내부 설계의 문제로 귀속된다. 이것은 책임의 증가이자 학습의 증가다.
### 운영의 윤리
대화 로그는 개선의 자원이다. 동시에 개인정보와 조직의 의도가 담긴 위험물이다. 셀프호스팅은 이 양면성을 숨길 수 없게 만든다.
최소한 다음을 문서로 남겨야 한다.
- 로그 저장 여부와 기간
- 민감정보 마스킹 정책
- 접근 권한과 감사 로그
- 삭제 요청 처리 절차
이 문서화는 조직이 자기 언어로 "기술의 윤리"를 정의하는 과정이다.
### 단일 GPU의 전략
GPU 1대 환경에서 흔한 실패는 "모든 것을 한 모델로" 해결하려는 욕망이다. 현실적인 전략은 다층 구성이다.
- 기본 대화/작성: 7B~14B instruct
- RAG: 임베딩 모델 + 재랭커 + 작은 생성 모델
- 고난도 작업: 필요할 때만 외부 API(하이브리드)
이 하이브리드는 패배가 아니라 성숙이다. 비용과 통제의 경계를 문제별로 나누는 것이기 때문이다.
---
## 결론
GPU 서버 한 대로 시작하는 LLM 셀프호스팅은 Ollama·vLLM·Open WebUI 같은 도구 덕분에 기술적으로는 더 이상 과격한 선택이 아니다. 그러나 의사결정의 본질은 여전히 어렵다. 비용, 지연, 통제, 책임, 윤리, 운영 역량이 한 덩어리로 묶여 있기 때문이다.
현상: API의 편의는 유지되지만 사용량·지연·통제·감사 요구가 누적되면 셀프호스팅이 다시 등장한다.
구조: 단일 서버에서는 단순함이 최적화다. vLLM은 서빙, Open WebUI는 채택을 담당한다.
본질: TCO는 감정의 논쟁을 끝내는 공통 언어다. 손익분기점은 "모델 가격"이 아니라 사용량과 운영 인건비의 함수로 결정된다.
함의: 셀프호스팅은 모델을 소유하는 것이 아니라 경계(데이터·지연·책임)를 내부로 재설계하는 일이며, 그 재설계가 조직의 사고를 성숙시킨다.
셀프호스팅의 성공은 "GPU를 샀다"가 아니라 어떤 것을 내부의 책임으로 받아들이고 어떤 것을 외부의 서비스로 남겨둘지 경계를 명료하게 그었는가로 판정된다.