백엔드 개발의 실무는 단순한 기능 구현을 넘어선다. 시스템의 지속 가능성을 설계하는 일이다. 성능 최적화는 병목을 제거하는 기술적 작업이면서 동시에 트레이드오프를 이해하고 선택하는 사유의 과정이다. 코드 리뷰는 논리적 일관성을 검증하는 집단 지성의 장이다. 이 글은 현업에서 마주하는 구조적 문제들을 통해 백엔드 시스템이 어떻게 진화하고 유지되는지 살펴본다.
성능 최적화: 측정 가능한 것만이 개선된다

백엔드 시스템의 성능 문제는 대부분 가시화되지 않은 채 누적된다. 응답 시간이 200ms에서 500ms로 늘어나는 과정은 점진적이고 은밀하다. 문제는 어느 순간 임계점을 넘어서며, 그때는 이미 구조적 개입 없이는 해결할 수 없는 지경에 이른다.
개발자의 직관은 종종 틀린다. 반복문이 느릴 것 같지만 실제로는 데이터베이스 커넥션 풀이 고갈되어 있고, API 호출이 병목일 것 같지만 실제로는 JSON 직렬화가 CPU를 잡아먹는다. 프로파일링은 이러한 추측을 배제하는 행위다. New Relic, Datadog, Elastic APM 같은 APM 도구가 제공하는 것은 단순한 지표가 아니라 시스템 내부의 인과 관계다.
측정의 대상은 명확해야 한다. 응답 시간(Latency), 처리량(Throughput), 에러율(Error Rate)은 서로 다른 차원의 건강성을 나타낸다. 응답 시간이 빠르더라도 처리량이 낮다면 동시성 문제가 있다. 처리량이 높더라도 에러율이 증가한다면 시스템이 한계에 도달한 것이다. P50, P95, P99 같은 백분위 지표는 평균이 감추는 극단값을 드러낸다. 평균 응답 시간 100ms는 안정적으로 보이지만 P99가 3초라면 1%의 사용자는 견딜 수 없는 경험을 하고 있다.
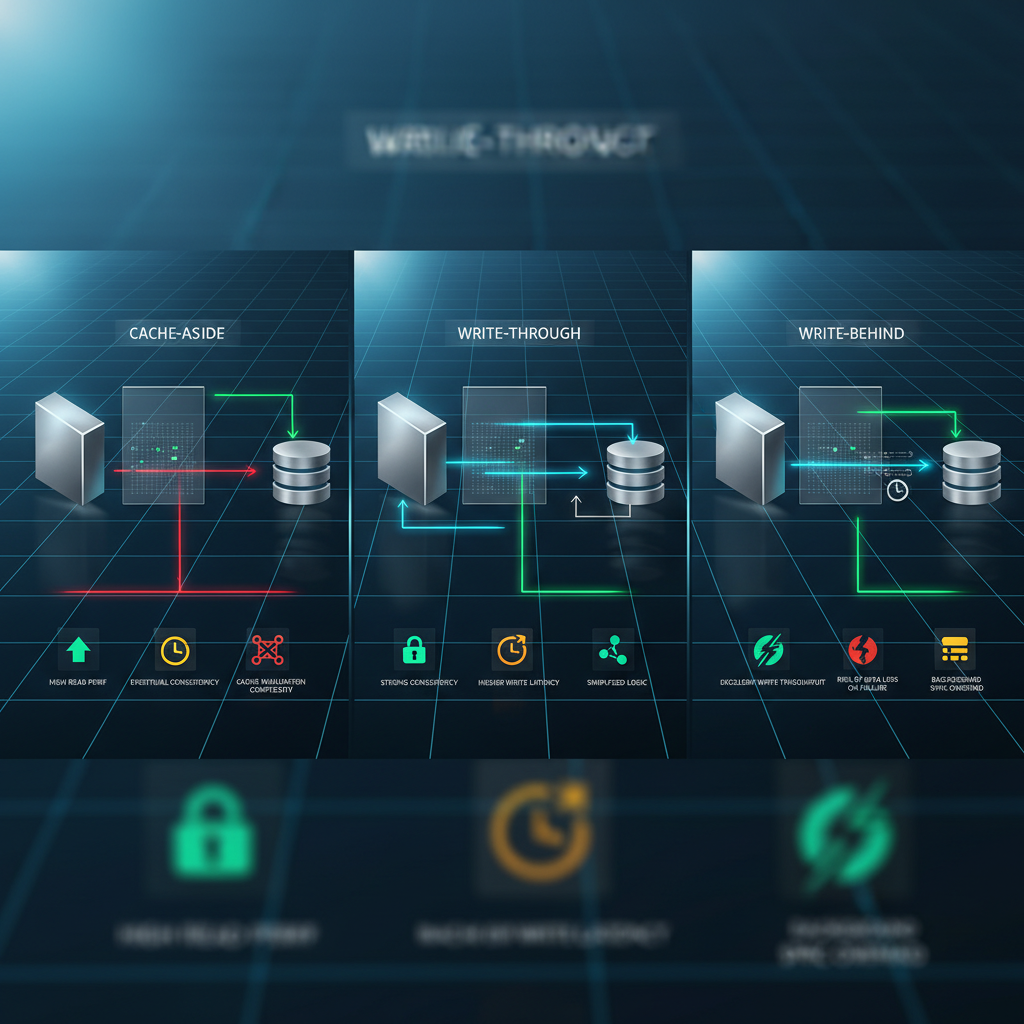
캐싱은 시간과 공간의 교환이다. Redis, Memcached 같은 인메모리 저장소는 디스크 I/O를 메모리 접근으로 대체한다. 하지만 캐시는 데이터의 신선도(Freshness)와 일관성(Consistency) 문제를 낳는다. TTL(Time To Live)을 짧게 설정하면 캐시 효율이 떨어지고, 길게 설정하면 오래된 데이터를 제공할 위험이 커진다. Cache-Aside, Write-Through, Write-Behind 같은 패턴은 각각 다른 트레이드오프를 내포한다. Cache-Aside는 구현이 단순하지만 캐시 미스 시 두 번의 네트워크 호출이 발생한다. Write-Through는 쓰기 성능을 희생하며, Write-Behind는 데이터 유실 가능성을 안고 간다.
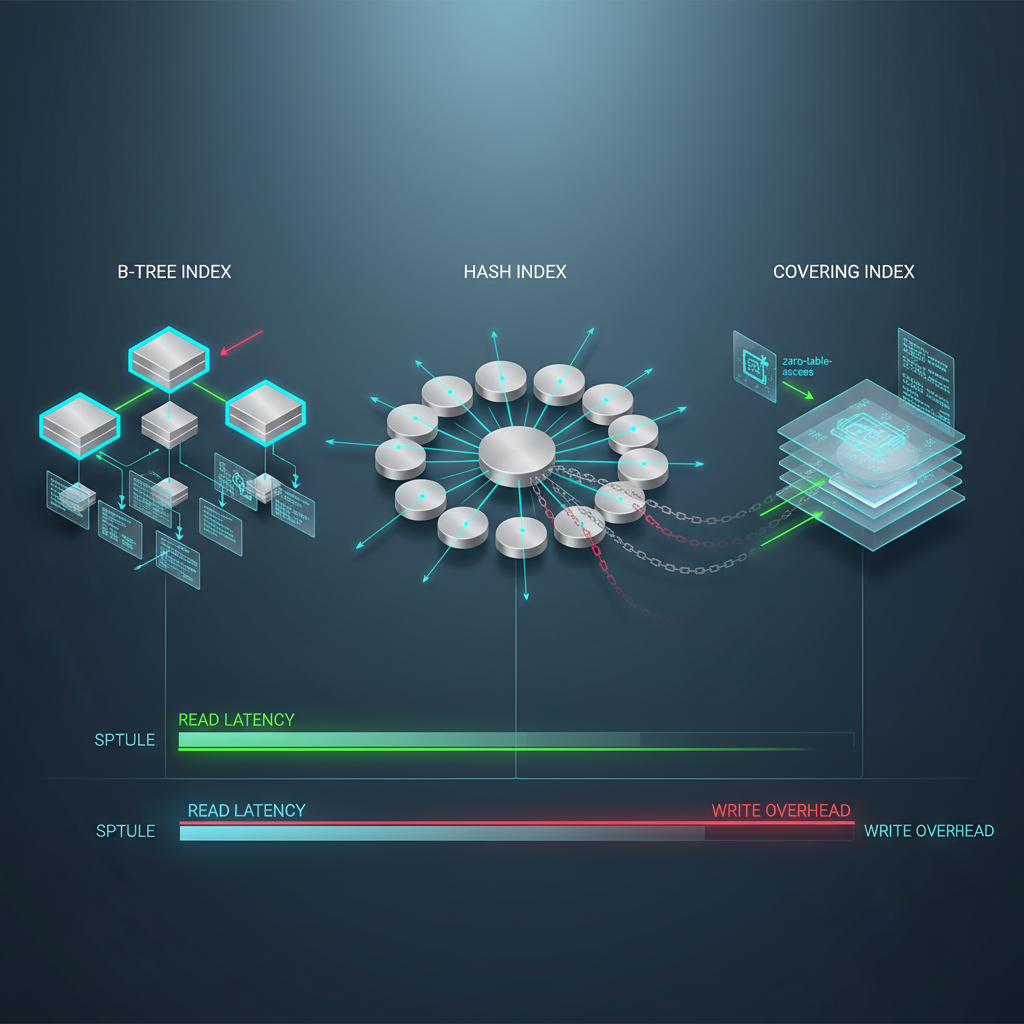
데이터베이스 쿼리 최적화는 인덱스 설계의 문제다. 인덱스는 읽기를 빠르게 하지만 쓰기를 느리게 한다. B-Tree 인덱스는 범위 검색에 유리하고, Hash 인덱스는 정확한 매칭에 최적화되어 있다. Covering Index는 인덱스만으로 쿼리를 해결해 테이블 접근을 제거하지만, 인덱스 크기가 커져 메모리 압박을 가한다.
N+1 쿼리 문제는 ORM의 지연 로딩(Lazy Loading)에서 빈번히 발생한다. 하나의 쿼리로 100개의 게시글을 가져온 뒤, 각 게시글의 작성자를 조회하기 위해 100번의 추가 쿼리가 실행되는 구조다. 이는 Eager Loading이나 JOIN으로 해결되지만, JOIN이 과도하면 쿼리 실행 계획(Execution Plan)이 복잡해져 오히려 성능이 저하된다.
비동기 처리는 응답성과 복잡도의 균형이다. 메시지 큐(RabbitMQ, Kafka, AWS SQS)를 도입하면 긴 작업을 백그라운드로 위임할 수 있다. 이메일 발송, 이미지 리사이징, 외부 API 호출 같은 작업은 사용자 요청의 응답 시간에 포함될 필요가 없다.
하지만 비동기 시스템은 새로운 실패 지점을 만든다. 메시지가 중복 전송될 수 있고(At-Least-Once Delivery), 순서가 보장되지 않을 수 있으며(Out-of-Order), 컨슈머가 죽으면 메시지가 유실될 수 있다. 멱등성(Idempotency) 설계는 필수다. 같은 메시지를 여러 번 처리해도 결과가 동일해야 한다.
코드 리뷰: 논리의 일관성을 검증하는 의식
코드 리뷰는 단순한 버그 발견 이상의 의미를 지닌다. 시스템의 논리적 일관성을 집단적으로 검증하는 과정이며, 개인의 암묵적 지식을 팀의 명시적 지식으로 전환하는 장이다.
리뷰의 초점은 계층에 따라 달라진다. 표면적 검토는 코딩 컨벤션, 네이밍, 포맷팅 같은 형식적 요소를 다룬다. 이는 린터(Linter)나 포맷터로 자동화 가능하며, 인간의 시간을 소모할 가치가 없다. ESLint, Prettier, Black 같은 도구는 이 계층의 논쟁을 종결시킨다.
구조적 검토는 설계의 타당성을 묻는다. 함수가 단일 책임을 지키는가? 모듈 간 의존성이 순환하지 않는가? 추상화 수준이 일관적인가? 예를 들어 비즈니스 로직 레이어에서 HTTP 요청 객체를 직접 다루는 것은 계층 분리 원칙을 위반한다. 컨트롤러는 요청을 파싱하고, 서비스는 도메인 로직을 처리하며, 리포지토리는 데이터 접근을 추상화해야 한다. 이 경계가 흐려지면 테스트 가능성이 떨어지고, 변경의 파급 효과가 예측 불가능해진다.
논리적 검토는 알고리즘의 정확성과 엣지 케이스 처리를 확인한다. 빈 배열이 입력되면? null이 반환되면? 동시에 두 요청이 같은 자원을 수정하면? 이러한 질문은 코드의 견고함을 시험한다.
경쟁 상태(Race Condition)는 분산 시스템에서 특히 치명적이다. 재고 차감 로직이 원자적(Atomic)이지 않으면 두 사용자가 동시에 마지막 재고를 구매할 수 있다. 낙관적 잠금(Optimistic Locking)이나 비관적 잠금(Pessimistic Locking)은 이를 방지하지만, 각각 재시도 로직 구현과 성능 저하라는 비용을 수반한다.
리뷰는 대화의 기술이다. "이 코드는 왜 이렇게 작성했나요?"라는 질문은 비난이 아니라 이해의 시도다. 리뷰어는 코드 작성자보다 컨텍스트가 부족하다. 명확하지 않은 부분은 코드 자체의 문제일 수 있고, 도메인 지식 부족일 수도 있다.
좋은 리뷰 코멘트는 구체적이고 건설적이다. "이 부분은 개선이 필요합니다"보다 "이 루프는 O(n²) 복잡도를 가지는데, HashMap을 사용하면 O(n)으로 줄일 수 있습니다"가 유용하다. 코드 리뷰는 지식 전파의 메커니즘이기도 하다. 시니어 개발자의 리뷰는 주니어에게 설계 원칙을 내재화시키고, 주니어의 질문은 시니어에게 암묵적 가정을 재검토하게 만든다.
아키텍처 결정: 선택의 무게를 견디는 법
백엔드 시스템의 아키텍처는 초기 결정이 장기적 제약으로 굳어진다. 모놀리식(Monolithic)과 마이크로서비스(Microservices) 사이의 선택은 단순한 기술 트렌드가 아니라 조직의 구조와 운영 능력을 반영한다.
모놀리식은 단순함의 가치를 지닌다. 하나의 코드베이스, 하나의 배포 단위, 하나의 데이터베이스. 트랜잭션은 ACID 속성을 보장하고, 디버깅은 단일 프로세스 내에서 완결된다. 초기 스타트업이나 작은 팀에서는 이 단순함이 생산성으로 이어진다. 하지만 코드베이스가 수십만 줄을 넘어서면 빌드 시간이 늘어나고, 작은 변경도 전체 배포를 요구하며, 팀 간 코드 충돌이 빈발한다.
마이크로서비스는 독립성과 복잡도를 교환한다. 각 서비스는 독립적으로 배포되고, 기술 스택을 자유롭게 선택하며, 장애가 격리된다. 하지만 분산 시스템의 본질적 어려움이 등장한다. 네트워크는 불안정하고, 서비스 간 호출은 지연을 누적시키며, 분산 트랜잭션은 일관성을 보장하기 어렵다. Saga 패턴, Event Sourcing 같은 복잡한 패턴이 필요해지고, 서비스 메시(Service Mesh), API 게이트웨이, 분산 추적(Distributed Tracing) 같은 인프라 오버헤드가 발생한다.
데이터베이스 선택은 데이터 모델의 선택이다. 관계형 데이터베이스(PostgreSQL, MySQL)는 정규화된 스키마와 강력한 일관성을 제공한다. JOIN, 트랜잭션, 외래 키 제약은 데이터 무결성을 보장하지만 수평 확장(Horizontal Scaling)이 어렵다.

NoSQL(MongoDB, Cassandra, DynamoDB)은 유연한 스키마와 수평 확장성을 제공하지만 일관성을 희생한다(Eventual Consistency). CAP 정리는 분산 시스템이 일관성(Consistency), 가용성(Availability), 분할 내성(Partition Tolerance) 중 두 가지만 동시에 보장할 수 있음을 증명한다. 실무에서는 네트워크 분할이 불가피하므로 일관성과 가용성 사이에서 선택해야 한다.
API 설계는 인터페이스의 안정성을 다룬다. RESTful API는 자원(Resource) 중심의 직관적 구조를 제공하지만, 여러 자원을 조합할 때 over-fetching이나 under-fetching 문제가 발생한다. GraphQL은 클라이언트가 필요한 데이터를 정확히 요청할 수 있게 하지만 쿼리 복잡도 제한과 N+1 문제 해결이 필요하다. gRPC는 Protocol Buffers 기반의 바이너리 통신으로 성능을 극대화하지만 브라우저 지원이 제한적이고 디버깅이 어렵다.
운영 가능성: 시스템이 살아남는 조건
코드가 프로덕션에 배포되는 순간, 개발은 끝나지 않고 운영이 시작된다. 운영 가능성(Operability)은 시스템이 예측 가능하게 실패하고, 빠르게 복구되며, 지속적으로 개선될 수 있는 능력이다.
로깅은 시스템의 기억이다. 구조화된 로그(Structured Logging)는 검색과 분석을 가능하게 한다. JSON 형식으로 timestamp, level, service, trace_id, message, context를 포함하면 ELK Stack(Elasticsearch, Logstash, Kibana)이나 Splunk 같은 도구로 집계할 수 있다.
로그 레벨(DEBUG, INFO, WARN, ERROR)은 신중하게 사용해야 한다. DEBUG는 개발 환경에서만, INFO는 주요 비즈니스 이벤트, WARN은 잠재적 문제, ERROR는 즉각 대응이 필요한 실패를 의미한다. 과도한 로그는 스토리지 비용을 증가시키고 중요한 정보를 희석시킨다.
모니터링은 관찰 가능성(Observability)의 기초다. 메트릭(Metrics), 로그(Logs), 트레이스(Traces)는 시스템을 이해하는 세 가지 관점이다. Prometheus는 시계열 메트릭을 수집하고, Grafana는 이를 시각화하며, Jaeger나 Zipkin은 분산 추적을 제공한다. 알람(Alerting)은 임계값 기반이 아니라 변화율 기반이어야 한다. "CPU 사용률이 80%를 넘으면"보다 "지난 5분 대비 에러율이 3배 증가하면"이 의미 있는 신호다.
배포 전략은 위험 관리의 문제다. Blue-Green 배포는 두 개의 동일한 환경을 유지하며 새 버전을 검증한 후 트래픽을 전환한다. 롤백이 즉각적이지만 인프라 비용이 두 배다. Canary 배포는 트래픽의 일부(예: 5%)만 새 버전으로 보내고, 메트릭을 관찰한 후 점진적으로 확대한다. 문제가 발견되면 영향 범위가 제한적이다. Rolling 배포는 인스턴스를 순차적으로 교체하며 무중단 배포를 가능하게 하지만, 배포 중 두 버전이 공존하므로 하위 호환성이 필수다.
장애 대응은 준비된 조직만이 효과적으로 수행한다. Incident Response Plan은 역할(Incident Commander, Communication Lead, Technical Lead)을 명확히 하고 절차(탐지, 완화, 복구, 사후 분석)를 정의한다.
사후 분석(Postmortem)은 비난이 아니라 학습의 도구다. "누가 실수했는가"보다 "어떤 시스템적 결함이 이 실수를 가능하게 했는가"를 묻는다. 비난 없는 사후 분석(Blameless Postmortem) 문화는 투명성을 장려하고 재발 방지책을 구체화한다.
지속 가능한 시스템을 향하여
백엔드 개발의 실무는 완성이 아니라 진화의 연속이다. 성능 최적화는 측정과 분석을 통해 병목을 제거하는 과정이며, 코드 리뷰는 집단 지성으로 논리적 일관성을 검증하는 의식이다. 아키텍처 결정은 트레이드오프를 이해하고 선택하는 행위이며, 운영 가능성은 시스템이 예측 가능하게 실패하고 빠르게 복구되도록 설계하는 능력이다.
기술적 선택은 언제나 맥락 속에 존재한다. 은탄환은 없으며, 모든 패턴과 도구는 특정 문제에 최적화되어 있다. 중요한 것은 도구 자체가 아니라 그것이 해결하려는 문제의 본질을 이해하는 것이다. 시스템은 코드로 구성되지만 코드는 사유로 설계된다. 지속 가능한 시스템은 기술적 탁월함과 운영적 성숙도가 균형을 이룰 때 비로소 가능하다.